Building an Amateur Intelligence

There is an emotional layer to every building. Human stories make buildings more than just assembled hard materials. Imagine you could give a building an anthropomorphic voice – a voice that is sometimes grumpy, sometimes bored, sometimes giddy, to tell its story. The voice would moderate and comment on all the little daily occurrences and events that happened inside the building. Instead of just being an inner monologue, the building would actually talk to its audience over its radio show.
After falling in love with this idea, we set out to create an “Artificial Intelligence Radio”. We wanted to build a likeable smart agent – embodied by a charismatic radio show host voice – that could see, hear, sense its environment and take action by way of a spoken language based on internal reasoning, knowledge, and memories. We also wanted the public to take part in forming the building’s personality and intelligence. That combined with our dilettante approach to A.I., we rechristened the project to “Amateur Intelligence Radio”. Luckily, the acronym “AIR“ stayed the same.
A distributed system
A general lesson in creating A.I. is to build your system with multiple distributed software components that run independently and in parallel, and therefore add robustness to the system. All components communicate with each other, yet if one of them fails, all others will still remain functional. Considering the scope of the system we had in mind, splitting everything up into components was not only logical, but also quite practical. We’d need several people for the developmental workload, and we’d need different programming language solutions for the different requirements and challenges we’d face along the way.
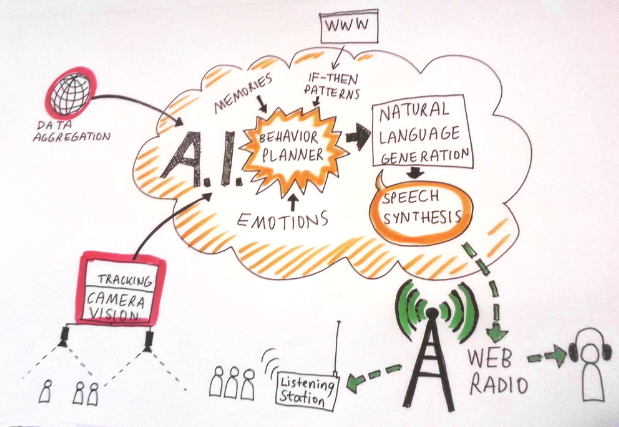
After having defined a rough system architecture, we divided AIR into its body parts and started the development work in an appropriate incremental fashion.
- EYES = computer vision (Emmanuel, blobserver, C++)
- SENSE = polling data from the web / environment (Eva, python)
- TOUCH = listening tech furniture (Michael, raspberry pi, python)
- BRAIN = the logic, decision making (François, python)
- KNOWLEDGE = website, API (Patrick & François, rails, python)
- LANGUAGE = natural language generation (Sylvain, python)
- VOICE = speech synthesis (Sylvain and Michael, acapela, C)
- ANTENNA = streaming radio (Sylvain, liquidsoap, icecast)
A building’s sensorium
Even though AIR was going to be a talking A.I., it did not fit within the criteria of a talking chatbot. While Eliza & Co. react to text input by exchanging in two-way communication, AIR was going to be more like a sports commentator: By observing a dynamic environment, all the while commenting on it.
After giving some thought to what constitutes the natural sensorium of an architectural structure (earthquake nausea, brick wall irritation), we decided to make the system smart yet not omniscient. AIR knows about St. Paul’s current weather conditions since it can feel heat and wind (parsed data from w1.weather.gov). The Depot has the Mississippi flowing right by it, so AIR can feel its speed and streamflow by way of ground data (parsed from water.weather.gov). Exactly like us, AIR lives in concordance with the earth’s light and darkness pattern, and knows when the sun will rise and the moon will set (computed with pyephem). Likewise it knows about the internal flow of buses and trains, by monitoring destinations and departure times (parsed from MetroTransit’s NexTrip). Just like every data-conscious radio host, it knows how many people tune in to listen (parsed from icecast stats). And finally in sports-arena style, it has a top-down vision onto its huge waiting room, where it can detect and track the movements of its visitors (built with blobserver).

Once the input flowing into the system was settled, we had to then design the dynamics to be found within the black box. These dynamics would judge the environment’s current conditions (thunderstorm, 10 visitors, bus to Chicago) and then create the next sentence to communicate (“I can only blame the weather for the fact that people want to leave St. Paul for Chicago.“).
A review of the field of Artificial Intelligence shows that there are two main approaches on how to build an intelligent system: The top-down symbolic approach (hard-code into its knowledge base what the letter A should look like geometrically) and the bottom-up connectionist approach (hold up a picture of the letter A many times so it can train its internal neural network to recognize it). Realizing that we probably wouldn’t be revolutionizing the field with our radio host, we decided the top-down approach would be more appropriate and easier to implement. We set out to design AIR’s brain similar to that of an expert system:
“ […] an intelligent agent designed to solve problems by reasoning about knowledge, represented primarily as IF–THEN rules rather than through conventional procedural code.”
In our case, the problem that AIR needed to solve was to decide what story to tell next. Emulating the decision-making ability of a human, AIR looks at the current state of its world (WORLD MODEL), compares that state to its repertoire of stories (KNOWLEDGE BASE), and then reasons and picks the most appropriate story to play next (DECISION MAKER).
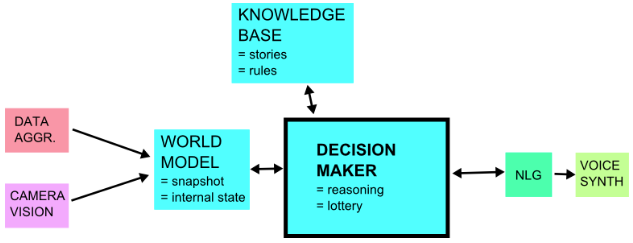
As AIR would not be able to generate smart talk out of thin air, we needed to give it a database full of stories, text snippets, and one-liners. To give these stories a context, we connected each story to a set of IFTTT-style rules, which represented the story’s trigger conditions. Each rule compares (>, <, ==, !=, %=) the state of one parameter of the system (wind velocity, day of week, online listeners, ..) to a customly set value. If all a story’s conditions are fulfilled – the results of the comparisons being TRUE – the story can be played next.

Yet obviously we didn’t want to compose a story for every single state (the systems’ world model being defined by over 60 parameters). This would result in a very inflexible and deterministic system, that would be a pain in the *** to update. So in order to leave room for surprise, we tied our stories to only one, two, or three of these parameters. That meant that at any given point in time, multiple stories would be suitable for the current state of the system.
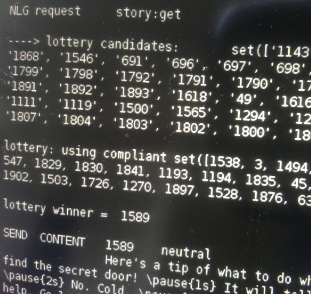
We could have then simply randomly picked one of these stories. But as in real life – when you are faced with multiple options to choose from, the chances are never evenly split – there are always preferences, logical reasons, and instincts leading to a more complex probability function. Considering that, we created the story lottery. Every story, whose trigger conditions apply, gets to enter the lottery. But each of them gets a different amount of lottery tickets based on how specific its conditions are (difficulty level), how recently the story was entered into the system (memory freshness), and how often it has been triggered before (uniqueness). After distributing all the lottery tickets, one ticket gets randomly picked and its owner wins the prestigious slot of being the next story to be communicated on air.
Knowing what it would say next, AIR now needed its voice. Speech synthesis has advanced a lot in recent years and the artificial voices that now surround us daily (subway announcements, Siri, etc) start to sound more and more convincing (have we reached the uncanny valley of sound yet?). On our hunt for good speech synthesis software, we learned that there are two basic synthesis approaches: Concatenative synthesis – which strings together segments of recorded human speech and therefore sounds more natural – and formative synthesis – which algorithmically modulates a waveform simulating voice and produces output more reliably intelligible, even at higher speeds.
For AIR our preference was to find a voice with character, a voice that you would enjoy listening to – even hours on end. Basically we wanted a cross between Ira Glass and Don LaFontaine. So we listened to and compared many artificial voices, finding a favorite in MaryTTS, a very impressive open-source text-to-speech system. But finally we went the proprietary-software way and chose Will of the acapela group, since his voice quality came closest to our ideal.
Will is based on a diphone sound database containing every possible sound in the English language. As a bonus, the voice donator for Will generously provided a range of what they call “vocal smileys”: Breathing, coughs, yawns, signs, sneezes, and swallows. Together, with the ability to adjust speed, pitch, and gain of a voice on the go, it provided enough variability and character for our radio show host. If you want to test Will (and his siblings) for yourself, you can do so in acapela’s online voice demo.
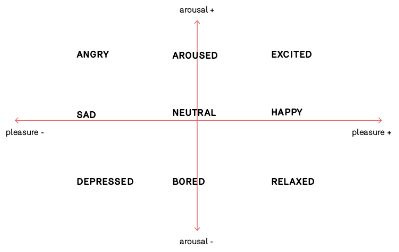
AIR now had stories to tell, a logical brain, and a voice. But to create a compelling personality we needed to add emotions to the mix. We wanted AIR to show excitement, experience anger, and to occasionally be utterly bored. We needed to learn about psychological models for emotions – a task that proved to be quite eye-opening. As it turns out, emotions – the part of human nature that we assume to be rather irrational – have quite a rational basis and can (quite) easily be mapped out onto numerical scales. A two- or three-dimensional space with a pleasure-arousal-dominance axis mapping (or even neurotransmitters) is enough to clearly define states such as compassion, stress, surprise, or anxiety.
For AIR we implemented a two-dimensional model based on Russell’s circumplex model of affect (1980). We specified 9 emotions – from sad to happy, from relaxed to excited – and mapped them along two axes: the pleasure and the arousal axes. All that needed to be accomplished still, was to specify AIR’s internal likes and dislikes: Its pleasure heightens with sunny weather, warm temperature, and new listeners, and its arousal fluctuates with increased quantities of visitors and moon visibility.
The result was a simple yet dynamic system: For example, when the Mississippi level rises above 8 feet – one of AIR’s major dislikes – the system’s pleasure level drops. Yet depending on the system’s current arousal level, the event can lead to an angry or a depressed radio show host.
AIR’s emotional state is naturally reflected in its voice. As we can modulate pitch and speed in the voice synthesis software, we tried to find a fitting parameter setting for each of our 9 emotions. With an additional slight fluctuation of those settings computed on the go, and the occasional yawns and sighs mixed in, AIR (hopefully) sounded less monotone. Besides using emotional states to sculpt its voice, we also created conditional rules for tying specific stories to specific emotions: Essentially, Happy stories for happy buildings.
Now would probably be a good time for you to go and meet AIR. You can listen to it at airstories.mn, and even contribute stories to its repertoire.
Final words: AIR has been our biggest software project yet and developing it proved to be quite an exciting challenge. Keeping track of all of its technical components (and I haven’t even talked much about the web, API, streaming server, and onsite listening technology) was/is a demanding task that has taught us a lot and most definitely led to our most extensive technical manual ever. Yet we are still not sick of listening to AIR’s voice and continue to happily add onto the growing bucket-list of additional features we’d love to implement if we do get around to 2.0 version:
- – generate the memory ability to refer back to previous world model states
- – implement a text-analysis NLG library to have AIR comment on stories
- – enable dynamic-variable integrations for user submissions on the website
- – create a dream state at night, where it markov-chain-style rehashes its daily transcript
And finally and foremost: Make AIR do math, so it can truthfully calculate the amount of time it would take a raindrop to drift from Minneapolis to the gulf of Mexico, based on the Mississippi’s current flow rate.